Part 1 of Decoder-Only Transformers from Scratch Series
Welcome to the first article of our multi-part series on building and training the foundations of what makes things like ChatGPT, Claude and Gemini work the way they do. The architecture is called a decoder-only transformer. By the end of this series, you’ll be able to fully understand the diagram below! Today we will look at tokenisation, embeddings, and the unembedding layer. I’ll assume you’re comfortable with basic linear algebra and have seen gradient descent before.
![]()
What does a decoder-only transformer actually do? At its core, the entire architecture has one job: given a sequence of tokens, predict the next token. That’s it. Every layer we’re about to walk through - embeddings, attention, feed-forward networks - exists to take the tokens seen so far and produce a probability distribution over the entire vocabulary for what should come next. The word “decoder” in “decoder-only” refers to this: the model decodes the most likely continuation of a sequence.
When ChatGPT writes a paragraph, it’s doing this one token at a time. It predicts token 1, appends it to the input, predicts token 2, appends it, and so on.
What is a Token?
“Claude Opus 4.7 has a context window of 1M tokens”
“Gemini 1.5 Pro has a context window of 2M tokens”
For readers that have heard of these numbers getting thrown around without any context (haha get it?) and wonder “what is a token really?”
A token is a fundamental unit of data (like bits in a computer, or genes in biology) in natural language processing (NLP) and it describes how letters, numbers, special characters and punctuations are broken up. A token can be anything from a single character, to chunks of characters assigned arbitrarily or through a given algorithm.
But why bother breaking text up at all? Neural networks do maths on numbers - matrix multiplications, additions, non-linear activations. They have no concept of a sentence or a word. You can’t multiply the string "cat" by a weight matrix. So before any of the neural network machinery kicks in, we need to (1) chop the input text into discrete pieces, and (2) assign each piece a number the model can actually work with. That’s what tokenisation gives us.
Tokenisation Schemes
Consider the following sentence. We’ll call the length of this sequence, measured in tokens, \(T\):
\[\text{The cat sat on the mat!}\]
Note that \(T\) is the length of whatever input the model is currently processing - it varies from one input to the next. A short prompt has a small \(T\), a long document has a much bigger one. Every model has a maximum \(T\) it can handle though, and that’s exactly what the context window numbers above refer to (so 1M tokens means \(T_{\max} = 10^6\)).
We can imagine breaking this sentence up into tokens in many different ways:
Character Level Tokenisation: Where we split each character as a separate token. So the sentence above becomes
['T', 'h', 'e', ' ', 'c', 'a', 't', ' ', 's', 'a', 't', ' ', 'o', 'n', ' ', 't', 'h', 'e', ' ', 'm', 'a', 't', '!']Word Level Tokenisation: Where we split the text based on some delimiter (in this case let’s take the space) as separate tokens. So the sentence above becomes
['The', 'cat', 'sat', 'on', 'the', 'mat!']Subword Level Tokenisation: Where we split the text based on some rule or algorithm. E.g. I want to take 4-length chunks as my tokens. So the sentence above becomes
['The ', 'cat ', 'sat ', 'on t', 'he m', 'at! ']
Before comparing these, one quick definition we’ll need:
The number of unique tokens that can be represented by a tokenisation scheme is called its vocabulary. Each unique token is assigned a token ID within this vocabulary set.
Each of these schemes comes with pros and cons:
| Tokenisation Scheme | Pros | Cons |
|---|---|---|
| Character-Level | Tiny vocabulary (e.g. 128 for ASCII). No out-of-vocabulary (OOV) tokens — every possible input can be represented. | Sequences become extremely long. “The cat sat on the mat!” becomes 27 tokens. This is a problem because attention has \(O(T^2)\) cost - doubling sequence length quadruples compute. Individual characters also carry almost no semantic meaning on their own. |
| Word-Level | Clean and intuitive - each token maps to a word humans recognise. Shorter sequences than character-level. | Vocabulary explodes. English has ~170,000 words in current use, and that’s before you count misspellings, slang, conjugations (run/ran/running/runs), and multilingual text. Any word not in the vocabulary becomes an <UNK> token, losing all information. |
| Subword-Level | Common words stay as single tokens (“the”, “and”), while rare words get broken into meaningful pieces (“un” + “break” + “able”). Keeps vocabulary manageable (~50K–130K) while handling novel words gracefully. | Tokenisation is no longer human-intuitive - word boundaries don’t always make linguistic sense. The best algorithms are also language-dependent since the rules are learnt from a training corpus: if they’re trained on English, it wastes tokens on Chinese/Japanese text, and vice versa. (Fun Fact - this is why some models are better at “token-efficient” code - their tokenisers were trained on more python/C++ files). |
Subword tokenisation gives us the best of both worlds: a manageable vocabulary size without sacrificing the ability to represent any input. This is why virtually every modern LLM uses some variant of it.
Vocabulary in Practice
To make this concrete: if we’re using character level tokenisation for ASCII text then the vocabulary size is 128 (95 printable characters - uppercase A-Z, lowercase a-z, 0-9, and symbols - and 33 non-printable control characters).
Modern LLMs like GPT, Claude and Gemini use their own proprietary tokenisation algorithms but a very common one used in many older GPT models and open-source models is called Byte-Pair Encoding (BPE). Andrej Karpathy has an excellent tutorial on BPE here but it’s a subword level tokenisation algorithm. If we want to tokenise the above sentence using the GPT Tokeniser, it would look something like this:


What is an Embedding?
Once we’ve converted an input text into tokens and assigned them their token IDs, we have a sequence of integers. But integers alone are not enough.
Here’s why: token IDs are arbitrary labels. The token for “king” might happen to be 4621 and the token for “queen” might be 9817 - those numbers are just slots in a lookup table, and the numerical gap between them means nothing. From the model’s perspective, “king” and “banana” are exactly as related as “king” and “queen”: they’re all just different integers. But we know “king” and “queen” are related concepts (same kind of entity, similar contexts, related meaning), and the same goes for “cat” and “dog”, or “Paris” and “London”. A model that takes raw token IDs as input has no way to express any of this - it’s starting from zero.
So we need a richer representation - one where the representation of “king” sits close to “queen” in some mathematical space, and far from “banana”. (We’ll make “close” precise in just a moment.) This is what embedding vectors give us.
An embedding vector is a higher-dimensional numeric representation for a particular token ID. Each embedding vector tries to capture nuances, connections and semantic meanings between tokens. We do this through an embedding layer.
An embedding layer is a matrix with \(d\) columns and \(V\) rows where \(V\) is the size of the tokeniser’s vocabulary and \(d\) is the dimensions of the embedding vector (or embedding dim). It acts as a lookup table for the token IDs.
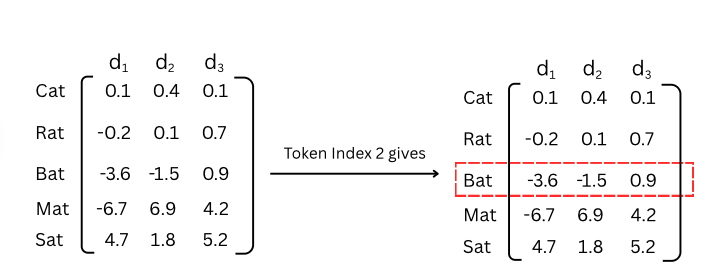
In practice, this is exactly what deep learning frameworks do - an optimised index lookup: embedding_matrix[token_id].
How the Embedding Lookup Actually Works
The figure above shows the intuition: to get the embedding for token ID 2, we just grab row 2 of the matrix.
Under the hood, this index lookup is mathematically equivalent to multiplying a one-hot vector by the embedding matrix.
A one-hot vector is a vector of length \(V\) (the vocabulary size) where every element is 0 except for a single 1 at the position of the token ID. For example, if our vocabulary has 5 words and we want token ID 2 (“Bat”), our one-hot vector is: \[\mathbf{x} = [0, 0, 1, 0, 0]\]
When we multiply this one-hot vector by the embedding matrix \(W_e\) of shape \([V \times d]\) we get:
\[\mathbf{e} = \mathbf{x} \cdot W_e = [0, 0, 1, 0, 0] \cdot \begin{bmatrix} 0.1 & 0.4 & 0.1\\ -0.2 & 0.1 & 0.7\\ -3.6 & -1.5 & 0.9\\ -6.7 & 6.9 & 4.2\\ 4.7 & 1.8 & 5.2\\ \end{bmatrix} = [-3.6, -1.5, 0.9]\]
The result is exactly row 2 of the matrix — the embedding vector for “Bat”. The one-hot vector acts as a selector: the 1 “activates” the corresponding row, and the 0s zero out everything else.
Measuring Similarity: The Dot Product
We’ve been using “close” loosely. Time to make it precise.
The standard way to measure similarity between two embedding vectors is the dot product:
\[\mathbf{a} \cdot \mathbf{b} = \sum_{i=1}^{d} a_i b_i\]
The geometric intuition is what matters here:
- Two vectors pointing in the same direction → large positive dot product.
- Two vectors pointing in opposite directions → large negative dot product.
- Two perpendicular vectors → dot product of 0.
So “close in meaning” really means “vectors that point in similar directions, giving a large dot product”.
A concrete toy example. Suppose our embedding dim is just 2 and, after training, we end up with:
\[\overrightarrow{\text{king}} = [4, 5] \qquad \overrightarrow{\text{queen}} = [4.5, 5.2] \qquad \overrightarrow{\text{banana}} = [-3, -4]\]
Then:
\[\overrightarrow{\text{king}} \cdot \overrightarrow{\text{queen}} = 4(4.5) + 5(5.2) = 18 + 26 = 44\]
\[\overrightarrow{\text{king}} \cdot \overrightarrow{\text{banana}} = 4(-3) + 5(-4) = -12 - 20 = -32\]
“king” and “queen” point in nearly the same direction, so their dot product is large and positive. “king” and “banana” point in roughly opposite directions, so theirs is large and negative. The dot product collapses the relationship between two vectors into a single number that captures how aligned (and therefore semantically similar) they are.
The raw dot product is sensitive to vector magnitude - a long vector will produce a big dot product with everything, even unrelated tokens. To handle this, people often use cosine similarity, which divides the dot product by the magnitudes of both vectors to give a clean score between \(-1\) and \(1\) regardless of vector length: \[\text{cos\_sim}(\mathbf{a}, \mathbf{b}) = \frac{\mathbf{a} \cdot \mathbf{b}}{\|\mathbf{a}\| \, \|\mathbf{b}\|}\]
This idea - that a dot product measures how aligned two vectors are - is going to come back in a big way when we get to attention, where dot products between query and key vectors are the core mechanism that lets one token “look at” another. For now, the takeaway is just: vectors close together in embedding space have large dot products, and that’s what “close in meaning” means.
The Geometry of Meaning
This is perhaps the most beautiful property of learned embeddings: the directions in embedding space encode semantic relationships.
A real embedding space might have \(d = 4096\) dimensions, which is impossible to picture. But a 2D toy version makes the idea concrete:
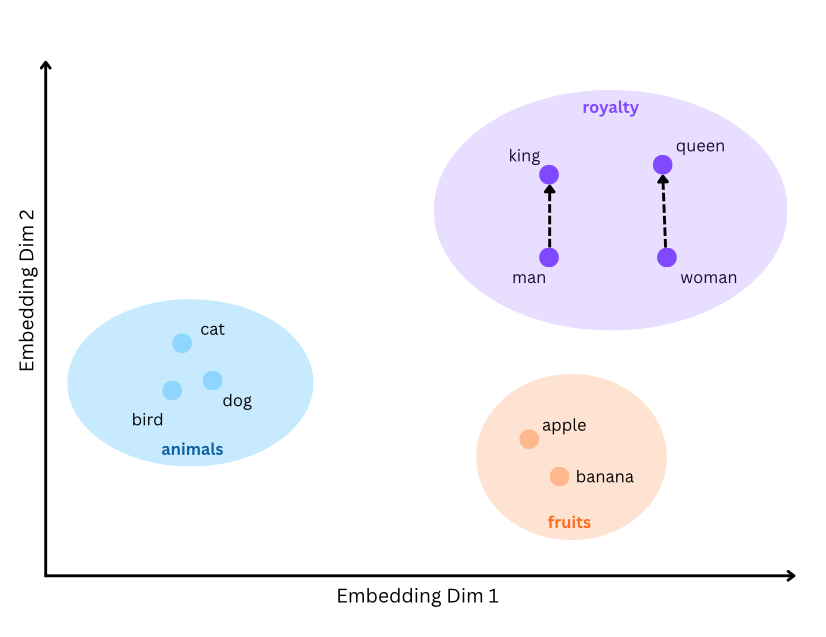
The classic demonstration is the king–queen analogy. After training, the following approximate relationship holds between word vectors:
\[\overrightarrow{\text{king}} - \overrightarrow{\text{man}} + \overrightarrow{\text{woman}} \approx \overrightarrow{\text{queen}}\]
What does this mean? The vector from “man” to “king” represents the concept of royalty. When we apply that same vector (that same direction and magnitude) starting from “woman”, we arrive near “queen”. The embedding space has organised itself so that analogous relationships correspond to parallel directions. Look back at the figure above - the dashed arrows from “man” to “king” and from “woman” to “queen” point the same way, which is exactly the geometry this equation describes.
Remarkably, this emerges purely from training on text data. The model learns that “king” and “queen” appear in similar contexts but differ in the same way that “man” and “woman” differ, and it encodes this pattern geometrically.
As a caveat, this is a simplified demonstration; real embedding spaces are far messier, but the principle that directions encode relationships holds broadly.
The Embedding Layer as a Learned Parameter
It’s worth emphasising: the embedding matrix is not hand-crafted or pre-computed. It is initialised randomly and trained alongside every other parameter in the model via gradient descent.
At the start of training, “king” and “queen” have random embedding vectors with no meaningful relationship. Over billions of training examples, the model adjusts these vectors so that tokens appearing in similar contexts drift closer together in embedding space, and the geometric structure described above emerges organically.
This has a subtle but important implication: the quality of your embeddings is bounded by the quality and quantity of your training data. If your training corpus contains very little medical text, the embeddings for medical terms will be poorly differentiated. If it contains biased associations (e.g. certain professions disproportionately linked with one gender), those biases will be encoded geometrically in the embedding space.
Dimensions & Scale
To ground this in reality, here are the actual embedding dimensions used by well-known open-source models:
| Model | Vocab Size (\(V\)) | Embedding Dim (\(d\)) | Embedding Parameters |
|---|---|---|---|
| GPT-2 | 50,257 | 768 | 38.6M |
| GPT-3 (175B) | 50,257 | 12,288 | 617.5M |
| LLaMA 2 (7B) | 32,000 | 4,096 | 131.1M |
| LLaMA 3 (8B) | 128,256 | 4,096 | 525.3M |
A few things stand out: The embedding layer alone can have hundreds of millions of parameters. GPT-3’s embedding matrix is \(50{,}257 \times 12{,}288 \approx 617\text{M}\) numbers. That’s a significant fraction of the total model - and this is just the lookup table before any actual computation happens. This is why we need to be careful with the vocabulary size and embedding dimension.
Larger \(d\) means richer representations but higher cost. Every subsequent layer in the transformer operates on vectors of size \(d\). Since attention has a cost proportional to \(d\) (more on this in a later post), doubling the embedding dimension affects the cost of every layer above it. This is the core architectural tradeoff: expressive embeddings vs. computational budget.
Notice LLaMA 3 quadrupled its vocabulary from LLaMA 2 (32K → 128K). A larger vocabulary means common multi-character sequences get their own token, which shortens sequences (fewer tokens per sentence = faster inference). But it also means a larger embedding matrix and a larger unembedding matrix.
We’ve now followed our input from raw text → tokens → embeddings → through the decoder blocks. The output is a matrix of shape \([T \times d]\) — one vector per position. But remember: the model’s job is to predict the next token. So we need to convert these abstract \(d\)-dimensional vectors back into a probability over every word in the vocabulary. That’s what the unembedding layer does.
The Unembedding Layer
At the very top of our architecture diagram sits the unembedding layer - the mirror image of the embedding layer.
Recall where we are. The input has passed through every decoder block, and the model has produced an output of shape \([T \times d]\) - one \(d\)-dimensional vector per token position. But the model’s job is to predict the next token, and that means producing a probability over the entire vocabulary. So we need to do two things: (1) get from a \(d\)-dimensional vector back to \(V\) numbers (one per possible next token), and then (2) turn those \(V\) numbers into a probability distribution. The unembedding layer handles step 1; the softmax function handles step 2.
Step 1: Project back to vocabulary space
The unembedding matrix \(\mathbf{W_u}\) has shape \([d \times V]\) and projects each output vector back into “vocabulary space”:
\[\text{logits} = \mathbf{h} \cdot \mathbf{W_u}\]
where \(\mathbf{h}\) is the \([T \times d]\) output from the final decoder block. The result is a \([T \times V]\) matrix of logits - one raw score per token in the vocabulary, per position in the sequence.
A logit is just a real number. It can be negative or positive, big or small. The interpretation is simple: a higher logit at position \(i\) for token \(k\) means “I think token \(k\) is a more likely continuation of the sequence so far”. The logits themselves aren’t probabilities though - which leads us to step 2.
Step 2: Logits → probabilities via softmax
To turn the logits into a proper probability distribution (positive numbers that sum to 1) we apply the softmax function:
\[P(\text{token}_i) = \frac{e^{\text{logit}_i}}{\sum_{j=1}^{V} e^{\text{logit}_j}}\]
Softmax does two things: exponentiate every logit (which makes everything positive and amplifies differences), then divide by the sum (which forces them to add to 1). What comes out is a valid probability distribution over the entire vocabulary, for every position in the sequence.
Because we want a full probability distribution - not just a winner, but how confident the model is across all candidates. This lets us sample creatively from the top-k most likely tokens rather than always picking the single most probable one. Softmax gives us exactly that.
The token with the highest probability is (roughly speaking) the model’s prediction for what comes next.
Weight Tying
Here’s an elegant detail: in many modern transformers, the unembedding matrix is the transpose of the embedding matrix: \[\mathbf{W}_u = \mathbf{W}_e^T\] This is called weight tying, and it means the model uses the same parameters for both “looking up” token meanings (embedding) and “predicting” tokens (unembedding). Intuitively this makes sense — if two tokens have similar embeddings (similar meanings), the unembedding should also score them similarly when predicting the next token. Weight tying also halves the parameter count of these two layers. For GPT-3, that’s saving roughly 617 million parameters. Not all models use weight tying (GPT-2 does, LLaMA does not), but it connects the top and bottom of the architecture diagram in a satisfying way: the same matrix that converts token IDs into meaning also converts meaning back into token predictions.
What’s Next
But these embedding vectors have no sense of order. “The cat sat on the mat” and “The mat sat on the cat” produce identical sets of embedding vectors — the model can’t tell them apart. Clearly, word order matters for meaning. That’s what positional encoding solves, and it’s the subject of the next post.